
















 JavaEE
JavaEE 鸿蒙应用开发
鸿蒙应用开发 HTML&JS+前端
HTML&JS+前端 Python+大数据开发
Python+大数据开发 人工智能开发
人工智能开发 电商视觉设计
电商视觉设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 集成电路应用开发
集成电路应用开发 C/C++
C/C++ 狂野架构师
狂野架构师 IP短视频
IP短视频


天富娱乐登录体育真人
天富娱乐登录 企业中谁知道网赌的网址的两种主要方式(谁知道网赌的网址、谁知道网赌的网址)
更新时间:2015年12月29日16时04分 来源:传智播客云计算学科 浏览次数:
企业中谁知道网赌的网址的两种主要方式(谁知道网赌的网址、谁知道网赌的网址)
2011年在海量数据处理领域,谁知道网赌的网址是人们津津乐道的技术,谁知道网赌的网址不仅可以用来存储海量数据,还以用来计算海量数据。因为其高吞吐、高可靠等特点,很多互联网公司都已经使用谁知道网赌的网址来构建数据仓库,高频使用并促进了谁知道网赌的网址生态圈的各项技术的发展。
下图是来自360图片搜索服务的图片,可以看看谁知道网赌的网址和storm所在位置。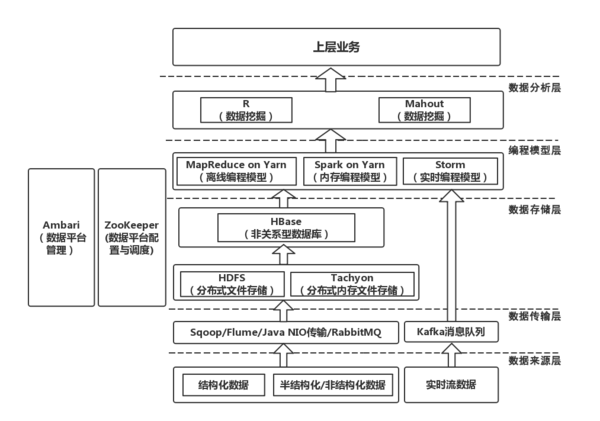
一般来讲,根据业务需求,数据的处理可以分为离线处理和实时处理,在离线处理方面谁知道网赌的网址提供了很好的解决方案,但是针对海量数据的实时处理却一直没有比较好的解决方案。就在人们翘首以待的时间节点,storm横空出世,与生俱来的分布式、高可靠、高吞吐的特性,横扫市面上的一些流式计算框架,渐渐的成为了流式计算的首选框架。如果庞麦郎在的话,他一定会说,这就是我要的滑板鞋!
在2013年前后,阿里巴巴开源了基于storm的设计思路使用java重现编写的流式计算框架jstorm。
那jstorm是什么呢?
在jstorm早期的介绍中,一般会出现下面的语句:J谁知道网赌的网址 比谁知道网赌的网址更稳定,更强大,更快,谁知道网赌的网址上跑的程序,一行代码不变可以运行在J谁知道网赌的网址上。
在最新的介绍中,jstorm的团队是这样介绍的:J谁知道网赌的网址 是一个类似谁知道网赌的网址 MapReduce的系统, 用户按照指定的接口实现一个任务,然后将这个任务递交给J谁知道网赌的网址系统,Jstorm将这个任务跑起来,并且按7 * 24小时运行起来,一旦中间一个Worker 发生意外故障, 调度器立即分配一个新的Worker替换这个失效的Worker。因此,从应用的角度,J谁知道网赌的网址 应用是一种遵守某种编程规范的分布式应用。从系统角度, J谁知道网赌的网址一套类似MapReduce的调度系统。 从数据的角度, 是一套基于流水线的消息处理机制。
实时计算现在是大数据领域中最火爆的一个方向,因为人们对数据的要求越来越高,实时性要求也越来越快,传统的谁知道网赌的网址 MapReduce,逐渐满足不了需求,因此在这个领域需求不断。现在,Jstom在淘宝海量的数据和大量的业务场景的锤炼下,从开始的追随者,使用者慢慢的演变成了流式计算技术的领导者。
2011年在海量数据处理领域,谁知道网赌的网址是人们津津乐道的技术,谁知道网赌的网址不仅可以用来存储海量数据,还以用来计算海量数据。因为其高吞吐、高可靠等特点,很多互联网公司都已经使用谁知道网赌的网址来构建数据仓库,高频使用并促进了谁知道网赌的网址生态圈的各项技术的发展。
下图是来自360图片搜索服务的图片,可以看看谁知道网赌的网址和storm所在位置。
一般来讲,根据业务需求,数据的处理可以分为离线处理和实时处理,在离线处理方面谁知道网赌的网址提供了很好的解决方案,但是针对海量数据的实时处理却一直没有比较好的解决方案。就在人们翘首以待的时间节点,storm横空出世,与生俱来的分布式、高可靠、高吞吐的特性,横扫市面上的一些流式计算框架,渐渐的成为了流式计算的首选框架。如果庞麦郎在的话,他一定会说,这就是我要的滑板鞋!
在2013年前后,阿里巴巴开源了基于storm的设计思路使用java重现编写的流式计算框架jstorm。
那jstorm是什么呢?
在jstorm早期的介绍中,一般会出现下面的语句:J谁知道网赌的网址 比谁知道网赌的网址更稳定,更强大,更快,谁知道网赌的网址上跑的程序,一行代码不变可以运行在J谁知道网赌的网址上。
在最新的介绍中,jstorm的团队是这样介绍的:J谁知道网赌的网址 是一个类似谁知道网赌的网址 MapReduce的系统, 用户按照指定的接口实现一个任务,然后将这个任务递交给J谁知道网赌的网址系统,Jstorm将这个任务跑起来,并且按7 * 24小时运行起来,一旦中间一个Worker 发生意外故障, 调度器立即分配一个新的Worker替换这个失效的Worker。因此,从应用的角度,J谁知道网赌的网址 应用是一种遵守某种编程规范的分布式应用。从系统角度, J谁知道网赌的网址一套类似MapReduce的调度系统。 从数据的角度, 是一套基于流水线的消息处理机制。
实时计算现在是大数据领域中最火爆的一个方向,因为人们对数据的要求越来越高,实时性要求也越来越快,传统的谁知道网赌的网址 MapReduce,逐渐满足不了需求,因此在这个领域需求不断。现在,Jstom在淘宝海量的数据和大量的业务场景的锤炼下,从开始的追随者,使用者慢慢的演变成了流式计算技术的领导者。
天富娱乐登录彩票
天富娱乐注册
0 分享到: 



















江苏天富娱乐注册股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号