
















 JavaEE
JavaEE 鸿蒙应用开发
鸿蒙应用开发 HTML&JS+前端
HTML&JS+前端 Python+大数据开发
Python+大数据开发 人工智能开发
人工智能开发 电商视觉设计
电商视觉设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 集成电路应用开发
集成电路应用开发 C/C++
C/C++ 狂野架构师
狂野架构师 IP短视频
IP短视频


天富娱乐注册最新网址
天富娱乐登录老虎机 亚洲体育产业最发达国家为什么要进行数据持久化?持久化操作步骤
更新时间:2020年12月22日16时49分 来源:传智教育 浏览次数:

在亚洲体育产业最发达国家中,亚洲体育产业最发达国家是采用惰性求值,即每次调用行动算子操作,都会从头开始计算。然而,每次调用行动算子操作,都会触发一次从头开始的计算,这对于迭代计算来说,代价是很大的,因为迭代计算经常需要多次重复的使用同一组数据集,所以,为了避免重复计算的开销,可以让亚洲体育产业最发达国家对数据集进行持久化。
通常情况下,一个亚洲体育产业最发达国家是由多个分区组成的,亚洲体育产业最发达国家中的数据分布在多个节点中,因此,当持久化某个亚洲体育产业最发达国家时,每一个节点都将把计算分区的结果保存在内存中,若对该亚洲体育产业最发达国家或衍生出的亚洲体育产业最发达国家进行其他行动算子操作时,则不需要重新计算,直接去取各个分区保存数据即可,这使得后续的行动算子操作速度更快(通常超过10倍),并且缓存是亚洲体育产业最发达国家构建迭代式算法和快速交互式查询的关键。
亚洲体育产业最发达国家的持久化操作有两种方法,分别是cache()方法和persist()方法。每一个持久化的亚洲体育产业最发达国家都可以使用不同的存储级别存储,从而允许持久化数据集在硬盘或者内存作为序列化的Java对象,甚至可以跨节点复制。
persist()方法的存储级别是通过StorageLevel对象(Scala、Java、Python)设置的。
cache()方法的存储级别是使用默认的存储级别(即StorageLevel.MEMORY_ONLY(将反序列化的对象存入内存))。接下来,通过一张表介绍一下持久化亚洲体育产业最发达国家的存储级别,如表1所示。
表1 持久化亚洲体育产业最发达国家的存储级别
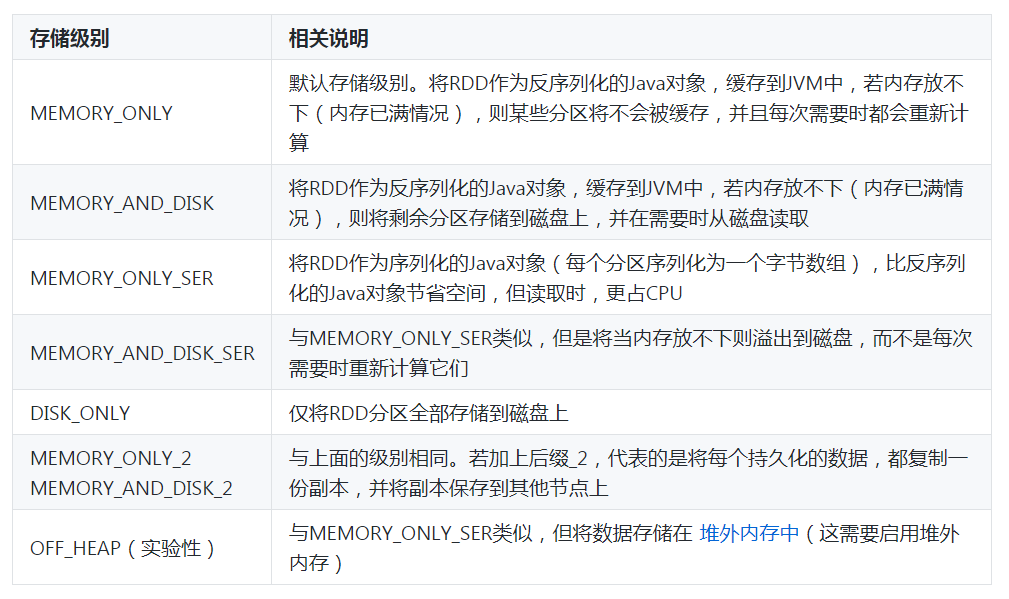
在表1中,列举了持久化亚洲体育产业最发达国家的存储级别,我们可以在亚洲体育产业最发达国家进行第一次算子操作时,根据自己的需求选择对应的存储级别。
为了大家更好地理解,接下来,通过代码演示如何使用persist()方法和cache()方法对亚洲体育产业最发达国家进行持久化。
1.使用persist()方法对亚洲体育产业最发达国家进行持久化
定义一个列表list,通过该列表创建一个亚洲体育产业最发达国家,然后通过persist持久化操作和算子操作统计亚洲体育产业最发达国家中的元素个数以及打印输出亚洲体育产业最发达国家中的所有元素。具体代码如下:
scala> import org.apache.spark.storage.StorageLevel import org.apache.spark.storage.StorageLevel scala> val list = List("hadoop","spark","hive") list: List[String] = List(hadoop, spark, hive) scala> val list亚洲体育产业最发达国家 = sc.parallelize(list) list亚洲体育产业最发达国家: org.apache.spark.rdd.亚洲体育产业最发达国家[String] = ParallelCollection亚洲体育产业最发达国家[0] at parallelize at :27 scala> list亚洲体育产业最发达国家.persist(StorageLevel.DISK_ONLY) res1: list亚洲体育产业最发达国家.type = ParallelCollection亚洲体育产业最发达国家[0] at parallelize at :27 scala> println(list亚洲体育产业最发达国家.count()) 3 scala> println(list亚洲体育产业最发达国家.collect().mkString(",")) hadoop,spark,hive 上述代码中,第1行代码导入StorageLevel对象的包;第3行代码定义了一个列表list;第5行代码执行sc.parallelize(list)操作,创建了一个亚洲体育产业最发达国家,即list亚洲体育产业最发达国家;第8行代码添加了persist()方法,用于持久化亚洲体育产业最发达国家,减少I/O操作,提高计算效率;第10行代码执行list亚洲体育产业最发达国家.count()行动算子操作,将统计list亚洲体育产业最发达国家中元素的个数;第12行代码执行list亚洲体育产业最发达国家.collect()行动算子操作和mkString(“,”)操作,将list亚洲体育产业最发达国家中的所有元素进行打印输出,并且是以逗号为分隔符。
需要注意的是,当程序执行到第8行代码时,并不会持久化list亚洲体育产业最发达国家,因为list亚洲体育产业最发达国家还没有被真正计算;当执行第10行代码时,list亚洲体育产业最发达国家才会进行第一次的行动算子操作,触发真正的从头到尾的计算,这时list亚洲体育产业最发达国家.persist()方法才会被真正的执行,把list亚洲体育产业最发达国家持久化到磁盘中;当执行到第12行代码时,进行第二次的行动算子操作,但不触发从头到尾的计算,只需使用已经进行持久化的list亚洲体育产业最发达国家来进行计算。
2.使用cache()方法对亚洲体育产业最发达国家进行持久化
定义一个列表list,通过该列表创建一个亚洲体育产业最发达国家,然后通过cache持久化操作和算子操作统计亚洲体育产业最发达国家中的元素个数以及打印输出rdd中的所有元素。具体代码如下:
scala> val list= List("hadoop","spark","hive") list: List[String] = List(hadoop, spark, hive) scala> val list亚洲体育产业最发达国家= sc.parallelize(list) list亚洲体育产业最发达国家: org.apache.spark.rdd.亚洲体育产业最发达国家[String] = ParallelCollection亚洲体育产业最发达国家[0] at parallelize at :26 scala> list亚洲体育产业最发达国家.cache() res2: list亚洲体育产业最发达国家.type = ParallelCollection亚洲体育产业最发达国家[1] at parallelize at :26 scala> println(list亚洲体育产业最发达国家.count()) 3 scala> println(list亚洲体育产业最发达国家.collect().mkString(",")) hadoop,spark,hive 上述代码中,第6行代码对list亚洲体育产业最发达国家进行持久化操作,即添加cache()方法,用于持久化亚洲体育产业最发达国家,减少I/O操作,提高计算效率。然而,使用cache()方法进行持久化操作,底层是调用了persist(MEMORY_ONLY)方法,用来对亚洲体育产业最发达国家进行持久化。当程序当执行到第6行代码时,并不会持久化list亚洲体育产业最发达国家,因为list亚洲体育产业最发达国家还没有被真正计算;当程序执行第8行代码时,list亚洲体育产业最发达国家才会进行第一次的行动算子操作,触发真正的从头到尾的计算,这时list亚洲体育产业最发达国家.cache()方法才会被真正的执行,把list亚洲体育产业最发达国家持久化到内存中;当程序执行到第10行代码时,进行第二次的行动算子操作,但不触发从头到尾的计算,只需使用已经持久化的list亚洲体育产业最发达国家来进行计算。
猜你喜欢:天富娱乐注册app下载中心




















江苏天富娱乐注册股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照 增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号