
















 JavaEE
JavaEE 鸿蒙应用开发
鸿蒙应用开发 HTML&JS+前端
HTML&JS+前端 Python+大数据开发
Python+大数据开发 人工智能开发
人工智能开发 电商视觉设计
电商视觉设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 集成电路应用开发
集成电路应用开发 C/C++
C/C++ 狂野架构师
狂野架构师 IP短视频
IP短视频


天富娱乐注册app下载中心 基于清洗方式的“脏”数据分类【大数据技术文章】
更新时间:2022年06月28日14时00分 来源:传智教育 浏览次数:
基于数据源的“脏”数据分类方法需要为每种类型的“脏”数据设计单独的清洗方式。从数据清洗方式的设计者角度看,可以将“脏”数据分为“独立型“脏”数据”和“依赖型“脏”数据”两类。基于清洗方式的“脏”数据分类如图下所示。
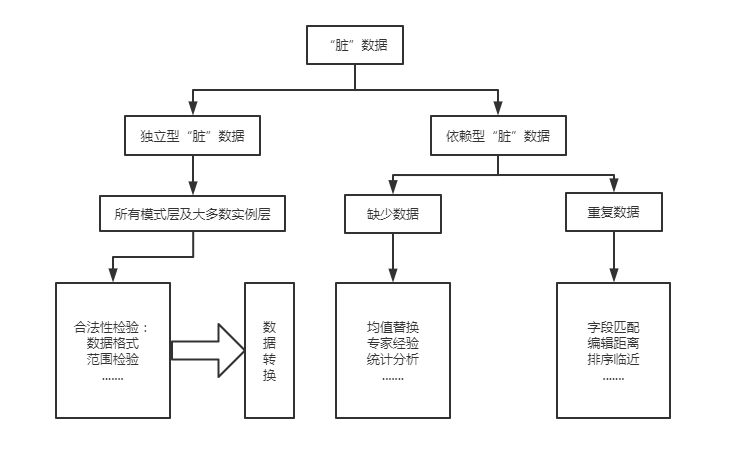
基于清洗方式的“脏”数据分类
从图1-2中可以看出,独立型“脏”数据包括单数据源和多数据源所有模式层及大多数实例层的数据质量问题;依赖型“脏”数据包括缺失数据和重复数据等“脏”数据。下面对独立型“脏”数据和依赖型“脏”数据进行详细讲解。
天富娱乐登录老虎机
独立型“脏”数据可通过记录或本身属性检验出是否包含“脏”数据,不需要依赖其他记录或属性检测。独立型“脏”数据使用“数据合法性检验规则”检测数据字段的实际内容,若属性值不符合规则,则视为“脏”数据,此时可调用已定义的相关清洗方式,将其变为满足规则的数据,从而可以保证数据的合法性。
合法性检验是判断数据是否符合给定标准的过程,判断标准是用户根据业务需要定义的一些检验规则,该规则主要检验的是数据的格式、数据的范围、数据的枚举清单以及数据的相关性等方面,具体介绍如下。
·数据的格式主要是检验记录的某个字段或字段组中的数据是否符合规范格式,这是针对模式层的“脏”数据进行检验。
·数据的范围主要是检查记录的字段数据是否在预期的范围内,常用于检验数字和有效值。
·数据的枚举清单主要是参照某个已定义的清单检验字段的值。
·数据的相关性主要通过主键和外键的关系实现。
综上所述,数据的合法性检验是一个非常耗时的环节,但也是一个必不可少的环节,因此,该环节应高度自动化。在设计清洗程序时,应该内置较多的检验函数和环节,这样可以减少用户定制数据合法性检验规则的工作量。
数据转换是将“脏”数据进行清洗的过程,包括模式转换和实例转换。其中,模式转换用来解决模式层“脏”数据的问题,通过在元数据库中定义表字段的映射规则、字段拆分规则以及字段值合并规则等协调数据模式之间的差异,从而实现数据的清洗;实例转换是根据源数据字段的实际内容,结合一定的领域知识解决拼写错误、输人错误、不同的计量单位及过时的编码等实例层“脏”数据问题。
天富娱乐注册注册网站
依赖型“脏”数据主要包括缺失数据和重复数据等“脏”数据。由于需要综合考虑与其他记录间的关联,依赖型“脏”数据的处理很难有通用的方法。一般地,针对特定类型的“脏”数据设计特定的清洗方式。
天富娱乐注册最新网址
缺失数据主要包括数据空值和数据异常,具体介绍如下。
数据空值一共有两种情况,即缺失值和空值。其中,缺失值是指值实际存在,但没有存入值所属字段中,如成年人都有身份证,若某个成年人的身份证号属性值为空,就属于缺失值;空值是指因实际并不存在而空缺的值,如动物没有身份证,因此它们的身份证号属性为空。
数据异常指的是用统计分析的方法识别出异常值。计算某个字段的平均值、众数、中位数以及最大值、最小值等,可根据这些统计的值和相关的规则发现数据中的异常。
天富娱乐登录
重复数据是指一个现实实体在数据集合中以多个不完全相同的记录表示。检测重复数据的方法有很多,例如基本的字段匹配、递归的字段匹配、Smith-Waterman算法以及基于编辑距离的字段匹配等方法。
天富娱乐登录




















江苏天富娱乐注册股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证  苏公网安备 32132202001156号
苏公网安备 32132202001156号