
















 JavaEE
JavaEE 鸿蒙应用开发
鸿蒙应用开发 HTML&JS+前端
HTML&JS+前端 Python+大数据开发
Python+大数据开发 人工智能开发
人工智能开发 电商视觉设计
电商视觉设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 集成电路应用开发
集成电路应用开发 C/C++
C/C++ 狂野架构师
狂野架构师 IP短视频
IP短视频


天富娱乐注册注册开户 亚新与亚星是一家吗意思? 正则化技术解析
更新时间:2019年09月12日17时49分 来源:传智播客 浏览次数:
正则化是广泛应用于机器学习和深度学习中的技术,它可以改善过拟合,降低结构风险,提高模型的泛化能力,有必要深入理解正则化技术。
奥卡姆剃刀原则
奥卡姆剃刀原则称为“如无必要,勿增实体”,即简单有效原理。在机器学习中,我们说在相同泛化误差下,优先选用较简单的模型。依赖于该原则,提出了正则化技术。
什么是正则化及正则化的作用
正则化是在经验风险项后面加上正则罚项,使得通过最小化经验风险求解模型参数转变为通过最小化结构风险求解模型参数,进而选择经验风险小并且简单的模型。
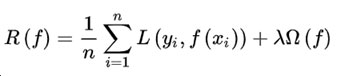
式中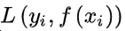 是经验风险项,
是经验风险项,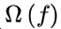 是正则项,
是正则项, 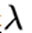 是正则化参数。
是正则化参数。
简单的模型拟合程度差(偏差大),泛化能力强(方差小);复杂的模型拟合程度好(偏差小),泛化能力弱(方差大)。
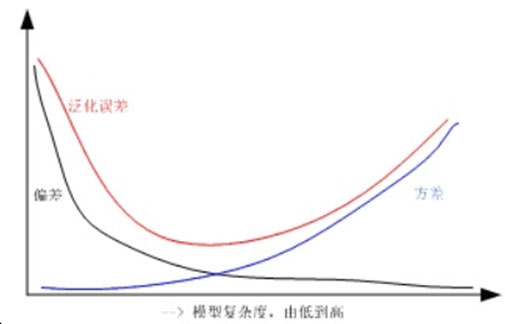
故选用合适的模型复杂度,使得泛化误差最小。
正则化的方法
正则化也可以称为规则化,在数学领域常称为范数,常用的有L1范数和L2范数。P范数的数学公式如下:
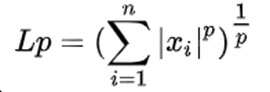
1) L0范数表示向量中非零元素的个数
2) L1范数表示向量元素的绝对值之和
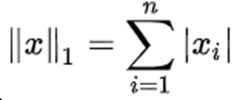
3) L2范数表示向量元素的平方和再开方
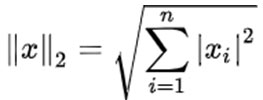
4) 范数表示所有向量元素绝对值中的最大值
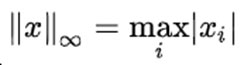
5) 范数表示所有向量元素绝对值中的最小值
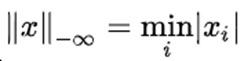
其中L1正则和L2正则是常用的正则化方法,L1正则可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择,同时可以防止过拟合。L2正则可以防止模型过拟合。L0范数一定可以保证得到稀疏模型,但L0范数的求解是NP难问题,实际中一般采用L1范数代替L0范数得到稀疏解,可以简单认为L1范数是L0范数的凸近似。
从图形角度分析L1正则与L2正则
从图形角度分析L1正则与L2正则,为简化分析,考虑只有两个权值向量w1和w2。
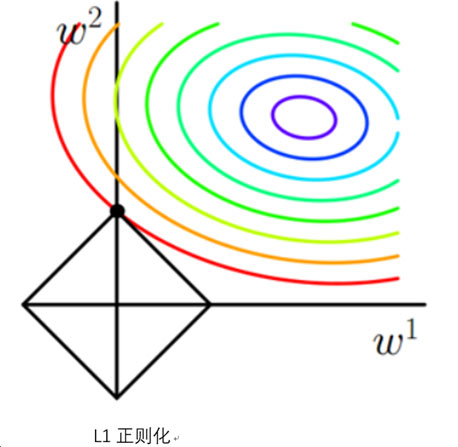
多彩的等值线代表经验损失函数解的空间,菱形线代表L1范数空间,当二者相交时,代表了一个结构损失函数的解,L1范数与经验损失函数的交点一般在坐标轴上,从而可以使得某些w=0,进而得到稀疏解。
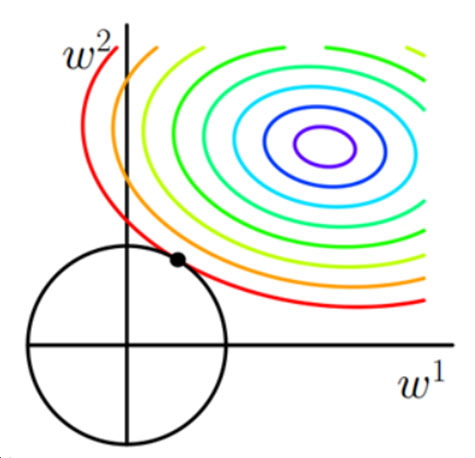
L2正则化
多彩的等值线代表经验损失函数解的空间,圆形线代表L2范数空间,L2范数与经验损失函数的交点一般接近于坐标轴上,可以改善过拟合,但不具有稀疏性。
从公式角度分析L1正则与L2正则
首先加入L2正则项后的损失函数形式:
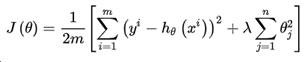
其中m为样本个数,n为特征个数,为了最小化损失函数,对各个模型参数求偏导后等于零即可求得估计值:
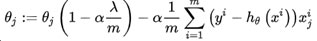
上式中,  是步长,
是步长,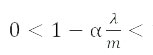 ,所以L2正则会对每一个模型参数
,所以L2正则会对每一个模型参数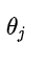 进行一定程度的缩减,但不会缩减为0。
进行一定程度的缩减,但不会缩减为0。
对于加入L1正则项后的损失函数形式:
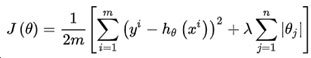
对各个模型参数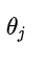 求偏导后等于零,可得:
求偏导后等于零,可得:
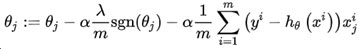
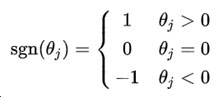
从上式可以看出:当上一轮θ_j大于0时,下一次更新θ_j一定减少,当上一轮θ_j小于0时,下一次更新θ_j一定增加,也就是说每一轮训练θ_j都是一定往0方向靠近,最终可得近似的稀疏解。
从贝叶斯角度分析L1正则与L2正则
从贝叶斯角度看,正则化相当于对模型参数引入先验分布:
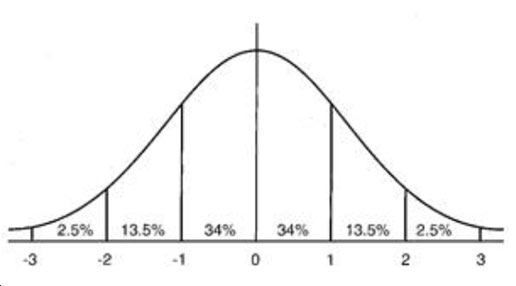
L2正则,模型参数服从高斯分布, ,对参数加了分布约束,大部分绝对值很小。
,对参数加了分布约束,大部分绝对值很小。
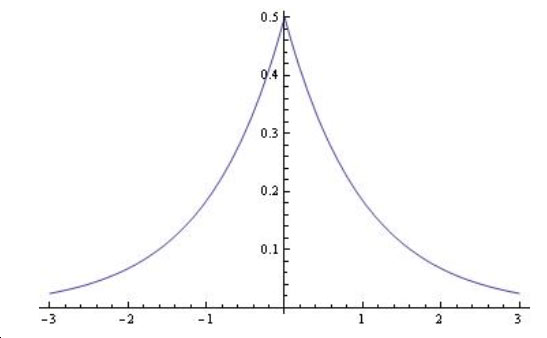
L1正则,模型参数服从拉普拉斯分布,对参数加了分布约束,大部分取值为0,这也解释了为何L1正则有获取稀疏模型的功能。
推荐了解:大数据课程
天富娱乐登录彩票




















江苏天富娱乐注册股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证  苏公网安备 32132202001156号
苏公网安备 32132202001156号